A couple of months ago, we wrote about CUDA, a programming model developed by NVIDIA to accelerate expensive computations. We explained why, in the context of ZK-SNARKs, it is useful for performing large multiplications.
Today, we want to discuss another development kit that provides an interface to communicate with the Graphics Processing Unit (GPU) called Metal. Metal was developed by Apple as an alternative for running code on GPUs in Mac systems. It provides its own programming language, called Metal Shading Language (MSL), for writing programs that can be executed by the GPU. Additionally, Metal provides an API designed for Swift or Objective-C to run functions written in MSL and manage resources between the CPU and GPU. In this post, we will use a Rust wrapper of this API called Metal-rs.
At the time of writing this post, we are building Lambdaworks, a library that makes it easy to program ZK-SNARKs. One of the essential operations required for using ZK-SNARKs is multiplication of polynomials that are of very high order. We can solve these operations efficently by using the Fast Fourier Transform (FFT) algorithm, which improves the complexity from 𝑂(𝑁2) to 𝑂(𝑁𝑙𝑜𝑔𝑁) (𝑁 being the order of the polynomial). Additionally, parallelizing all the work of this algorithm in the GPU could lead to even better results when working with these large polynomials. So that is our end goal.
The goal of this post is to learn the basics of MSL and see how to do simple computations with it. Then, we will provide a general overview of what is needed to implement FFT on the GPU. We will use the Rust Language to execute these functions and manage the resources between the CPU and GPU.
Metal Structures
Metal has some general structures for facilitating communication between the CPU and GPU. To create structures in the app, which can then be passed to the GPU for executing a function, there are some necessary steps. Let’s take a look at how they work.
Metal Thread Hierarchy
The basic idea behind parallel computation in the GPU is to run a massive amount of threads organized in different structures. Each thread is responsible for executing a portion of the overall computation, and all of these threads run simultaneously.
In our previous post about CUDA, we covered in detail how threads are organized, and Metal’s thread structure is quite similar. To help you understand how it works, we’ll give a brief recap, but if you want to learn more, you can check out that section.
Threads are identified in a grid by a coordinate system that depends on the dimensions of the grid. For a 2D grid, the coordinate system would be (x, y). Threads are primarily grouped in threadgroups, which are further divided into Warps or SIMD groups. Threads in a warp execute the same instructions concurrently on different data, meaning that if a single thread in the warp were to diverge (e.g. because of an if statement) then the whole warp will execute both branches and hurt performance
Understanding this structure is essential when deciding how to split computations between threadgroups and which sizes to use for each group. We’ll provide more detail on this topic when we cover some basic examples.
Metal Device
The core of the Metal API is the Device, which is an abstraction that represents a GPU in code. You can identify different GPUs and use them for different purposes, but for simplicity’s sake, we’ll just use the default and let Metal automatically select the GPU from our system.
Command Queue
In addition to the Device, another essential object to use in Metal is the Command Queue. This represents a basic queue that receives commands, such as packages for execution on the GPU. It’s called a queue because it has a specific order in which things are executed. The command queue not only receives our inputs and functions for execution, but also a lot of other things that are necessary for Metal to work.
Command Buffers
When we talked about “packages” while explaining the Command Queue, we were actually referring to Command Buffers. These buffers work as storage for the functions and computations that we want to execute on the GPU. They don’t run the computations when they are created, but when they are pushed to the Command Queue. There are a few Command Buffers for different types of actions, but the ones that we are interested in are the compute commands.
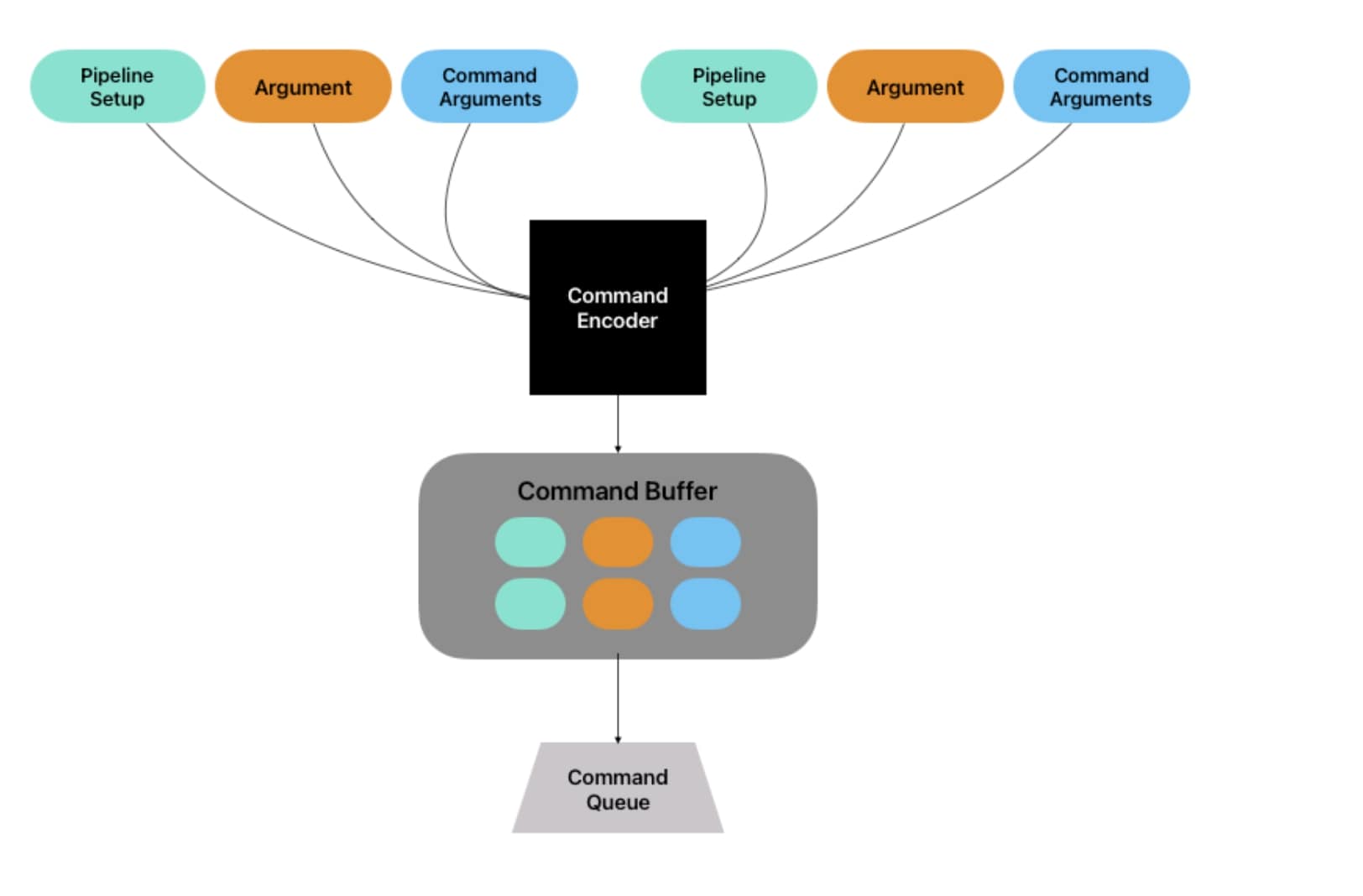
Pipeline State
This structure represents the GPU state that needs to be set for a specific command. It is initialized with a specific library, which is basically all the code written in MSL that we want to run, and provides all the necessary steps for the GPU to execute it.
Encoders
For each type of command that we want to run on the GPU using Metal, we use a dedicated type of encoder. However, all encoders serve the same purpose of creating a package that will be our command buffer. The encoder takes all the arguments of the function that we want to run, as well as its arguments and the pipeline state, and creates a package that will be executed on the GPU. One encoder can be used to create multiple commands, which will be packaged in the same command buffer.
It is important to inform Metal when we have finished encoding all the commands, so that it can push all the created buffers to the queue. We can summarize all these new structures and how they communicate with the following diagram:

To better understand how all these structures work together, it is helpful to see some basic examples.
Programming in MSL and Rust
For the first example we will compute a basic product between arrays.
First let see how our function looks in MSL:
dotprod.metal
[[kernel]]
void dot_product(
constant uint *inA [[buffer(0)]],
constant uint *inB [[buffer(1)]],
device uint *result [[buffer(2)]],
uint index [[thread_position_in_grid]])
{
result[index] = inA[index] * inB[index];
}
GPU programs are typically referred to as shaders which contain functions of different types. The kernel keyword in this context means that this is a compute function (made for running parallel computations) and makes it accessible from our Rust code. Since we are working with a kernel, we can specify which kind of thread grid it will run on.
Some arguments can be in different address spaces, constant and device in our case. Data in the device space is available for the device’s (another way to call the GPU) to read and write into. Data in the constant space is read-only.
You may notice that the function does not contain a for loop or any similar iteration to execute the product on the array. This is because multiple threads will work in parallel, executing this operation on different positions of the arrays. When we define the dimensions of our grid and the number of threads to use, each thread is assigned a specific position (the index parameter) to execute the task simultaneously. We use this for indexing, mapping one thread to one element in both arrays.
Lastly, the [[buffer(id)]] is an attribute which identifies that a kernel argument points to a specific buffer, which is a collection of data in memory that can be shared between the CPU and the GPU. When we define these buffers (on our main app), we set an index for the GPU to create a pointer to the buffer and use it accordingly. The 0, 1, 2 refer to the indexes of the different buffers that we want the kernel to access. To simplify this further, we create the arrays in the Rust code and then copy them to the buffers. The GPU uses these indexes to know where to read and write. Although the attributes are not necessary (buffers will be maped to arguments in order), it’s a best practice to use them.
Okay, that’s it for the MSL part, so let’s switch to Rust.
First we have to declare our Device, that is our abstraction of the GPU in the code.
let device: &DeviceRef = &Device::system_default().expect("No device found");
In this case we let Metal assign a default GPU to use.
Next, we need to reference the function written in MSL. For that, we need to compile our .metal code to generate a .metallib file that will be the library that our Rust code will use. To compile our metal file, we need to run the following command:
xcrun -sdk macosx metal -c dotprod.metal -o dotprod.air
xcrun -sdk macosx metallib dotprod.air -o dotprod.metallib
You’ll need Xcode tools for this, you can see how to install it here.
Actually, this command will create two new files:
- One with
.airextension which is an intermidiate language that apple recommends to compile first. - The
.metallibfile that will contain our compiled MSL library.
Now, we can include the new lib in our Rust code
const LIB_DATA: &[u8] = include_bytes!("dotprod.metallib");
And get a reference to the lib and our function
let lib = device.new_library_with_data(LIB_DATA).unwrap();
let function = lib.get_function("dot_product", None).unwrap();
Now that we have our metal lib and the function that we want to execute, we can create the Pipeline
let pipeline = device
.new_compute_pipeline_state_with_function(&function)
.unwrap();
Next, we declare all the buffers. These buffers are copies of the structures created in Rust (arrays v and w) of the portion of memory that is shared between the CPU and the GPU.
let length = v.len() as u64;
let size = length * core::mem::size_of::<u32>() as u64;
let buffer_a = device.new_buffer_with_data(
unsafe { mem::transmute(v.as_ptr()) }, // bytes
size, // length
MTLResourceOptions::StorageModeShared, // Storage mode
);
let buffer_b = device.new_buffer_with_data(
unsafe { mem::transmute(w.as_ptr()) },
size,
MTLResourceOptions::StorageModeShared,
);
let buffer_result = device.new_buffer(
size, // length
MTLResourceOptions::StorageModeShared, // Storage mode
);
We’re dealing with two arrays of u32 data type, so the first thing to do is get the size in bytes of both arrays. When using the new_buffer_with_data() method, we’re essentially creating a buffer that copies the data we’re pointing to (the transmute() function reinterprets a *u32 raw pointer into a *c_void). Finally, we define the storage mode. There are a few modes available for different purposes, but for this case, we use the Shared mode, which simply creates a buffer in the system memory that is accessible from both GPU and CPU. We want buffer_result to be an empty buffer, so we only need to specify its size.
Now, we create the rest of our structures
let command_queue = device.new_command_queue();
let command_buffer = command_queue.new_command_buffer();
let compute_encoder = command_buffer.new_compute_command_encoder();
compute_encoder.set_compute_pipeline_state(&pipeline);
compute_encoder.set_buffers(
0, // start index
&[Some(&buffer_a), Some(&buffer_b), Some(&buffer_result)], //buffers
&[0; 3], //offset
);
Note that we define the index of our buffers in the offset parameter when we call set_buffers. That indexing is what the GPU uses to know where the resource is that it has to use. This is exactly the same as
compute_encoder.set_buffer(0, Some(&buffer_a), 0);
compute_encoder.set_buffer(0, Some(&buffer_b), 1);
compute_encoder.set_buffer(0, Some(&buffer_result), 2);
Now is the time to set up the grid and threads that will be used in our function:
let grid_size = metal::MTLSize::new(
length, //width
1, // height
1); //depth
let threadgroup_size = metal::MTLSize::new(
length, //width
1, // height
1); //depth;
compute_encoder.dispatch_threads(grid_size, threadgroup_size);
As shown in the snippet above, the grid has a width, height and depth, just like the threadgroup. For this example, we can think of having a one dimensional grid that is our array, with the width being the length of the array. With this sizes we will have one thread per element in our array, which is exactly what we need, considering that each thread will execute a product between two elements. After all that, we simply dispatch the threads to the encoder.
That concludes the encoding and all the resources we need to be able to execute the task on the GPU, so now we can commit.
compute_encoder.end_encoding();
command_buffer.commit();
command_buffer.wait_until_completed();
The function wait_until_completed() is needed to get the results of the program but consider that the CPU will stop executing things until the GPU is finished with the task. This may not be the best solution in some cases and you may prefer to run another function after the buffer work is done via command_buffer.add_completed_handler().
If we want to check that the multiplication was done right in the GPU, we need access to the content of our buffer_result.
let ptr = buffer_result.contents() as *const u32;
let len = buffer_result.length() as usize / mem::size_of::<u32>();
let slice = unsafe { slice::from_raw_parts(ptr, len) };
We get the pointer to the memory location of the result buffer and the exact length of the buffer to get all the elements of our array. Using that pointer with the calculated length, we can get a slice with the multiplied elements.
All the code for this example can be found in this Metal Playground repository.
Learning FFT
We learned how all the communication with the GPU works, so now we want to see what exactly the FFT algorithm is, and why it is a great candidate to be executed on the GPU.
DFT and how FFT speed things up
To begin, let’s discuss another widely used algorithm in the field of physics that is closely related to FFT – the Discrete Fourier Transform (DFT).
In brief, the DFT algorithm is a mathematical operation that converts a sequence of complex numbers into another sequence of complex numbers. For our specific use case, we are interested in how we can perform faster polynomial multiplication. As multiplying two polynomials involves computing the product of each pair of coefficients and adding the resulting terms with the same degree, it requires 𝑂(𝑁2) operations for two polynomials of degree 𝑁. We can do better than that.
Our polynomials are typically represented using their coefficients, which we call a coefficient representation. However, we can also represent a polynomial with a series of points – precisely 𝑛+1 points. It turns out that the product of two polynomials in the coefficient representation is equal to the pointwise multiplication of their point value representation, followed by a transformation of that result back to coefficients. Therefore, all we need is a way to transform the polynomial coefficient representation to a point value representation and then back to the coefficient representation, and that’s exactly what DFT and its inverse (IDFT) do.
The transformation from coefficient form to point value form is known as the evaluation process of the polynomial, while the other way around is known as the interpolation process. However, the problem with DFT is that it does not improve the complexity of the overall computation because it performs all this magic in 𝑂(𝑁2) operations too. This is where FFT comes in handy.
The Fast Fourier Transform (FFT) algorithm is a computational technique used to efficiently compute the DFT by exploiting its symmetry and periodicity properties. The FFT algorithm uses a divide-and-conquer approach, where the coefficients are recursively divided into smaller sub-polynomials, and the DFT of each sub-polynomial is computed separately.
The key idea behind the FFT algorithm is to decompose the DFT computation into a series of smaller, atomic DFTs, called butterflies, that can be computed efficiently using multiplication and addition operations. The FFT algorithm significantly reduces the number of operations required to compute the DFT from 𝑂(𝑁2) to 𝑂(𝑁∗𝑙𝑜𝑔(𝑁)), making it a practical solution for large polynomials.
A FFT algorithm can have different characteristics, such as if it uses a Decimation in Time or Decimation in Frequency approach (changes the butterfly operation), if it’s n-radix (meaning that it divides the problem in n every time) or mixed-radix (divides the problem in multiple sizes), if its ordered or not and which order does it handles, and a big etcetera.
Since the entire algorithm is based on dividing the problem into two, it’s essential to ensure that the polynomials have an order that is a power of 2.
That is a lot of information so let’s see a basic overview of these ideas:

Working with finite fields
As mentioned earlier, we explained that the DFT works with complex numbers, but in our case, that won’t be necessary because all of the polynomials and calculations are done in finite fields. A finite field is a mathematical set with a finite number of elements satisfying certain algebraic properties, namely that you can sum, multiply and divide just like you can with regular numbers.
The most common finite fields have a prime number of elements (called the order of the field), so they are also called prime fields. Essentially, these are just the integers with the sum and multiplication done modulo the prime order, that is, operations “wrap around” when they go over it. If you’re interested in learning more about modular arithmetic and how it works, you can check out this resource.
Twiddle factors
One key aspect to understanding how the FFT algorithm works is the concept of twiddle factors. These factors are essential to exploiting the symmetry and periodicity properties of polynomials and enable the evaluation process to be completed with fewer operations. Typically, these factors are referred to as roots of unity – complex numbers that equal 1 when raised to some integer power 𝑛. As we previously mentioned, since we are working with finite fields, the twiddle factors used in our calculations are not complex numbers, but rather elements within the field.
For example, in the field with elements 0,1,2,3,4,5,6 with order 𝑝=7, the number 6 will be a 2𝑛𝑑 root of unity since 62𝑚𝑜𝑑7=1
During the process of implementing FFT, it is crucial to calculate a specific number of roots of unity. However, in order to ensure that these calculations are both accurate and feasible, we require a specific characteristic for the prime fields we use. Specifically, the prime order of the fields must follow the form of 2𝑛𝑘+1, where the 𝑛 is referred to as the “two-adicity” of the field. This condition guarantees that we can compute all necessary roots of unity to successfully carry out the FFT algorithm.
Furthermore, when calculating the twiddle factors, we will determine a “primitive root of unity”, which enables us to easily obtain other primitive roots by raising it to the required 𝑛𝑡ℎ power.
This is just an introduction to the FFT algorithm, so don’t worry if everything isn’t clear yet. There are many intricacies involved in making this algorithm work, and additional calculations are required. To learn more about the FFT algorithm and how it operates, we highly recommend watching this excellent video.
Summary
Metal serves as a great alternative to CUDA on Mac systems, allowing us to perform expensive computations much faster. However, using Metal requires an understanding of its structures and new concepts in addition to the algorithm and code we want to run. We hope this post helped provide some clarity on those concepts.
On another note, we’ve been exploring FFT, one of the greatest and most commonly used algorithms in the ZK world. Some of the mathematical concepts behind FFT are more complex and we want to explain those topics more in depth with more examples. Stay tuned for future posts on this exciting topic to learn how to bring it to code.